
Introduction
I ran /inspect twice on a large PR.
- First pass: found 12 findings → fixed them all.
- Second fresh-eye pass (same PR, same review pattern, different prompt): found 5 additional issues: 1 Critical and 4 Important.
This post breaks down the bugs that appeared only in the second review pass. It is a concrete example of why “fresh perspective” matters in AI pair-programming.
Background — Why Review Twice?
After building CheckUS’s TV dashboard system — 18 modes, 5 vertical slices, and 60+ backend classes — I ran the first /inspect pass and fixed 12 findings.
In theory, that should have been enough. The AI reviewer had already gone through a 4-pass review: Correctness, Conventions, Security, and Completeness. But I still ran a second pass:
Same code, fresh prompt, different perspective. Did the first pass miss anything?
It did. Five more issues appeared. One of them was Critical, and it was a case where the first pass had interpreted the problem in the opposite direction.

Case 1 — The Bug the First Pass Read Backwards
First-pass report: “Global content gate is missing in TvContentController.update() — TEACHER can create global content (Important).”
First-pass fix: add a DEVELOPER role check.
// after the first fix
if (existing.campusId() == null
|| (request.campusId() == null && request.campusId() != existing.campusId())) {
requireDeveloper();
} else {
validateAccess(existing.campusId());
}
Second-pass finding (Critical): this condition blocks a normal case.
request.campusId() != existing.campusId() is reference equality for Long != Long in Java. There is no unboxing here. And when request.campusId() == null is true, null != someNonNullLong is always true.

So a normal partial update where campusId is omitted gets misread as a global-content modification attempt and is blocked. The first pass saw “possible authorization bypass”; the second pass found the opposite effect: a normal path was blocked.
The root cause is that a Java record does not distinguish between null and “field absent.” If UpdateTvContentRequest.campusId() is null, you cannot tell whether the client meant “no change” or “set it to null.”
Second-pass fix: block campusId changes in the service. Force global ↔ campus conversion to happen through delete + recreate.
@Transactional
public TvContentResponse update(Long contentId, UpdateTvContentRequest req) {
TvContent content = contentRepository.findById(contentId).orElseThrow(...);
// campusId changes are not allowed in PUT.
// global ↔ campus conversion must be delete + recreate.
if (req.category() != null) content.setCategory(req.category());
if (req.title() != null) content.setTitle(req.title());
// ... other fields
}
The controller became simpler too: if the existing content is global, require DEVELOPER. Otherwise validate campus access. Done.
Case 2 — Race Window Between existsBySlug and INSERT
First-pass report: slug conflict handling works (existsBySlug + BusinessException).
Second-pass finding: concurrent request race window. If another request inserts the same slug after existsBySlug passes but before INSERT, the DB unique constraint (uk_tv_profile_slug) throws a raw DataIntegrityViolationException, and users see a generic 500.
Second-pass fix:
@Transactional
public TvProfileResponse create(Long campusId, CreateTvProfileRequest req) {
if (profileRepository.existsBySlug(req.slug())) {
throw ErrorCode.TV_PROFILE_SLUG_CONFLICT.toException();
}
TvProfile profile = ...;
try {
return profileRepository.save(profile);
} catch (DataIntegrityViolationException e) {
// Concurrent request used the same slug after existsBySlug passed.
log.warn("TvProfile slug conflict (race window): slug={}", req.slug());
throw ErrorCode.TV_PROFILE_SLUG_CONFLICT.toException();
}
}
Catch the DB exception explicitly and convert it to the same business error. The UI gets a consistent message.
Case 3 — Timezone: Depending on Browser Local Time
First-pass report: D-day calculation shows negative values from December 1 to 22 → add next-year advance logic.
First-pass fix:
function nextThirdThursdayOfNovember(): Date {
const now = new Date();
let target = thirdThursdayOfNovemberForYear(now.getFullYear());
if (target.getTime() < now.getTime()) {
target = thirdThursdayOfNovemberForYear(now.getFullYear() + 1);
}
return target;
}
function thirdThursdayOfNovemberForYear(year: number): Date {
return new Date(year, 10, day, 8, 40, 0); // browser local time
}
Second-pass finding: new Date(year, 10, ...) uses the browser’s local timezone. It works in a KST environment, but kiosk-mode headless browsers, UTC servers, or VPN-routed environments can shift the time by nine hours.
Second-pass fix: make the timezone explicit.
function thirdThursdayOfNovemberKst(year: number): Date {
// Date calculation is timezone-independent: compute weekday in UTC.
const nov1Utc = new Date(Date.UTC(year, 10, 1));
const dayOfWeek = nov1Utc.getUTCDay();
const offsetToFirstThu = (4 - dayOfWeek + 7) % 7;
const day = 1 + offsetToFirstThu + 14;
// KST 08:40 = UTC 23:40 previous day. Date.UTC handles hour=-1 overflow.
return new Date(Date.UTC(year, 10, day, 8 - 9, 40, 0));
}
function currentKstYear(): number {
return Number(new Intl.DateTimeFormat('en-CA', {
timeZone: 'Asia/Seoul', year: 'numeric',
}).format(new Date()));
}
Use Intl.DateTimeFormat(timeZone: 'Asia/Seoul') to extract the KST year explicitly. It stays correct regardless of browser timezone.
datetime-local conversion followed the same pattern: new Date(localValue + ':00+09:00') to explicitly mark KST.
Case 4 — N+1: 5-second Polling Hits the DB Every Time
First-pass report: tv-interrupt output is cached with a 90-second TTL.
Second-pass finding: the interrupt resolver is cached, but its caller, PublicTvProfileService.getInterrupt(), still calls findBySlug() every 5 seconds. No cache there.
1 TV = 5-second polling → 17,280 profile lookups per day
10 TVs → 172,800 lookups per day
Second-pass fix: cache slug → metadata (campusId, scheduleId, customMessages) for one minute.
@Cacheable(value = "tv-profile-slug-meta", key = "#slug")
public InterruptContext getInterruptContext(String slug) {
return profileRepository.findBySlug(slug)
.map(p -> new InterruptContext(p.getCampusId(), p.getScheduleId(), p.getCustomMessages()))
.orElseThrow(...);
}
public Optional<InterruptResponse> getInterrupt(String slug) {
InterruptContext ctx = getInterruptContext(slug); // 1-minute cache
long minuteBucket = System.currentTimeMillis() / 60_000L;
return interruptResolver.resolve(...); // 90-second cache
}
With the two-layer cache — slug → metadata for 1 minute, computed interrupt result for 90 seconds — the 5-second polling path mostly becomes cache hits.
Case 5 — Missing Cache Invalidation
First-pass report: stale data is operationally acceptable because the cache TTL is only one minute.
Second-pass finding: when an admin changes profile metadata (slug, customMessages), there is no cache eviction. For one minute, stale slug → campus mapping can survive. An admin can create a new slug and send it to operations, while another user still hits the old slug and gets a null-campus lookup failure.
Second-pass fix: evict related caches when metadata changes.
@Transactional
@Caching(evict = {
@CacheEvict(value = "tv-profile-slug", allEntries = true),
@CacheEvict(value = "tv-profile-slug-campus", allEntries = true),
@CacheEvict(value = "tv-profile-slug-meta", allEntries = true),
@CacheEvict(value = "tv-interrupt", allEntries = true),
@CacheEvict(value = "tv-battle", allEntries = true)
})
public TvProfileResponse update(Long campusId, Long profileId, UpdateTvProfileRequest req) { ... }
allEntries = true is acceptable here because the cache is small, capped around 200 entries.
Result
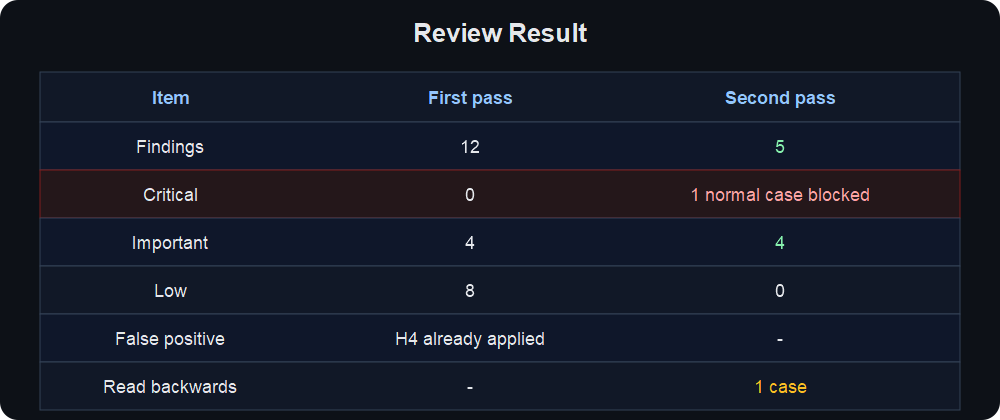
Four of the five second-pass findings came from areas the first pass did not focus on: N+1, race window, cache invalidation, and timezone. One finding came from an area the first pass had seen, but interpreted in the opposite direction.
Lessons Learned
1. AI reviewers see different things depending on prompt design. The first prompt focused on spec compliance, conventions, and security. The second prompt focused on whether the first fix introduced new bugs, plus operational scenarios and end-to-end flow. Same 4-pass pattern, different emphasis, different findings.
2. A second pass can discover the opposite effect. The first pass saw “authorization bypass.” The second pass saw “normal case blocked.” Both were pointing at the same broken logic from different directions.
3. One Critical finding justifies the second review cost. If I had committed after the first fix, production would have received a user report: TEACHER cannot edit their own campus content. The second review cost — tokens plus about 30 minutes — was far cheaper.
4. Java record + null semantics is a risky pattern.
A record is immutable, but it cannot express “field absent.” In partial update APIs, null can mean either “do not change” or “set to null.” Use explicit PUT semantics or a clearXxx flag pattern.
5. Cache invalidation should be designed when the cache is added. The first pass added caching but missed invalidation. The second pass added eviction. When you write cache code, also answer: “Where does this data change?”
References
- Spring
@CacheEvictguide - Java record + Optional discussion
- Intl.DateTimeFormat — MDN
- Related post: If You Typed the Same Sentence 60 Times, That’s a Skill — the workflow that came out of repeatedly asking for a fresh-eye review
Comments