
일요일 오전, 서버가 먹통이 됐다. 로그인도 안 되고, 다른 endpoint도 안 된다. 로그를 열어보니 Apparent connection leak detected 경고가 2초 사이에 6건 터져 있었다.
DB 커넥션 풀이 고갈된 것이다. 원인을 추적해보니 백엔드 쿼리 하나의 성능 문제에 프론트엔드의 불필요한 리페치가 증폭기 역할을 했다. 흥미로운 점은, 이 백엔드 안티패턴을 한 달 전에 이미 다른 곳에서 발견하고 수정했었다는 것이다.
사고 현장
HikariCP 로그:
02:51:38 WARN Connection leak detected (thread tomcat-handler-5188)
02:51:39 WARN Connection leak detected (thread tomcat-handler-5191)
02:51:40 WARN Connection leak detected (thread tomcat-handler-5204)
02:51:40 WARN Connection leak detected (thread tomcat-handler-5205)
02:51:40 WARN Connection leak detected (thread tomcat-handler-5206)
02:51:40 WARN Connection leak detected (thread tomcat-handler-5211)
커넥션 풀 크기는 10개. 6개가 leak으로 잡혔다. 스택트레이스를 따라가니 범인이 보였다:
at TaskListController.listItems(...)
at TaskListController.listDynamicItems(...)
목록 API 두 개가 커넥션을 오래 잡고 있었다.
원인 1: Cartesian Product (백엔드)
listItems 쿼리를 보면:
@Query("SELECT DISTINCT t FROM Task t " +
"LEFT JOIN FETCH t.assignees " + // @ManyToMany — 컬렉션
"LEFT JOIN FETCH t.tags " + // @ElementCollection — 컬렉션
"WHERE t.orgId = :orgId")
두 개의 컬렉션을 동시에 FETCH JOIN하고 있다. 시각화하면:
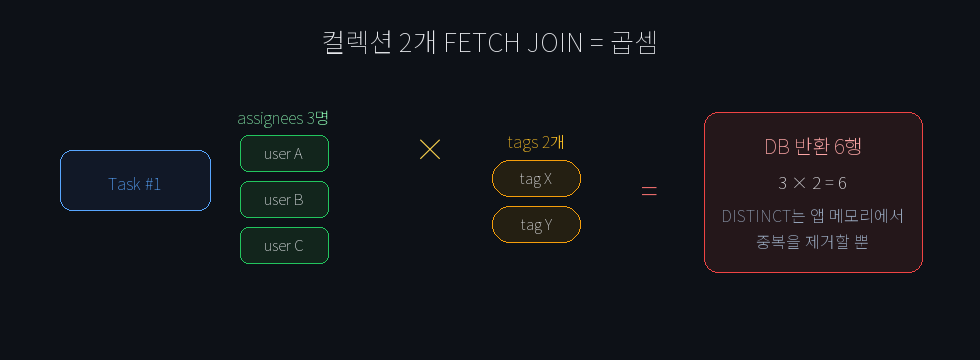
DISTINCT를 써도 DB에서 애플리케이션으로 전송되는 데이터량은 줄지 않는다. Hibernate가 메모리에서 중복을 제거할 뿐이다. 데이터가 쌓이면서 쿼리 실행 시간이 30초를 넘기기 시작했다.
수정
tags의 JOIN FETCH를 제거하고 @BatchSize로 대체:
// Entity에 BatchSize 추가
@ElementCollection(fetch = FetchType.LAZY)
@BatchSize(size = 100)
private Set<String> tags = new HashSet<>();
// Repository에서 한쪽만 FETCH
@Query("SELECT DISTINCT t FROM Task t " +
"LEFT JOIN FETCH t.assignees " +
"WHERE t.orgId = :orgId")
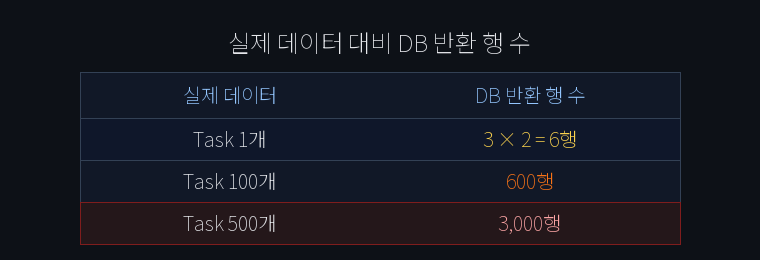
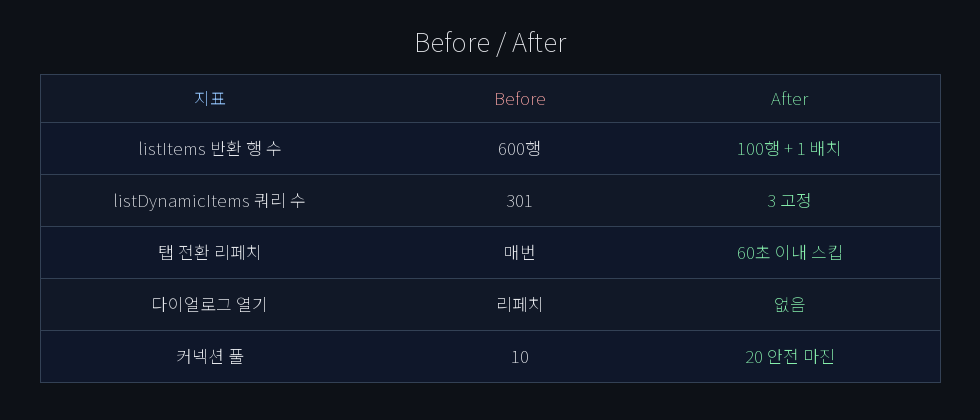
100개 task 기준: 600행 → 100행 + 1개 배치 쿼리.
원인 2: Correlated Subquery (백엔드)
listDynamicItems 쪽에도 문제가 있었다. “미래 예약된 이벤트가 없는 활성 멤버” 목록을 조회하는 쿼리:
SELECT mp,
(SELECT MAX(e.occurredAt) FROM Event e
WHERE e.userId = up.userId AND e.occurredAt < :now),
(SELECT MAX(t.firstActivityAt) FROM MemberTransition t
WHERE t.memberProfile = mp AND ...),
(SELECT MAX(t.activatedDate) FROM MemberTransition t
WHERE t.memberProfile = mp AND ...)
FROM MemberProfile mp
WHERE ...
SELECT절에 3개의 correlated subquery가 있다. 활성 멤버 N명이면 DB가 내부적으로 3N번의 서브쿼리를 실행한다. N이 100이면 301번의 쿼리 비용이 하나의 SQL 안에서 발생한다.
수정: 2단계 배치 조회
// Step 1: 메인 쿼리 (서브쿼리 없이)
List<MemberProfile> profiles = entityManager.createQuery("""
SELECT mp FROM MemberProfile mp
JOIN FETCH mp.userProfile up
JOIN FETCH up.user u
WHERE mp.orgId = :orgId
AND mp.status = :activeStatus
AND NOT EXISTS (...)
""", MemberProfile.class).getResultList();
// Step 2a: 마지막 이벤트 시각 — 배치 조회
Map<Long, LocalDateTime> lastEventMap = entityManager.createQuery("""
SELECT e.userId, MAX(e.occurredAt)
FROM Event e
WHERE e.userId IN :userIds AND e.occurredAt < :now
GROUP BY e.userId
""", Object[].class).getResultList()...;
// Step 2b: 첫 활동/가입일 — 배치 조회
Map<Long, Object[]> transitionMap = entityManager.createQuery("""
SELECT t.memberProfile.id,
MAX(t.firstActivityAt),
MAX(t.activatedDate)
FROM MemberTransition t
WHERE t.memberProfile.id IN :profileIds AND ...
GROUP BY t.memberProfile.id
""", Object[].class).getResultList()...;
N × 3 서브쿼리 → 고정 3개 쿼리. N이 아무리 커도 쿼리 수는 변하지 않는다.
원인 3: 프론트엔드 증폭기
백엔드 쿼리가 느린 건 필요조건이었고, 충분조건은 프론트엔드에 있었다.
staleTime = 0 (기본값)
React Query의 기본 staleTime은 0이다. 데이터를 가져오자마자 stale로 표시된다. 그 결과:
사용자 액션 React Query 동작
───────────────────────── ────────────────────
탭 전환 (포커스 lost) ────► 다음 포커스 시 refetch
컴포넌트 mount/unmount ────► 재마운트 시 refetch
다른 페이지 갔다 복귀 ────► refetch (stale → fresh)
window focus regain ────► refetch (default)
→ 사용자 1명의 액션이 30초 쿼리 2개를 N번 반복 실행
사용자가 목록 탭을 열었다가 다른 페이지를 보고 돌아올 때마다, 30초짜리 쿼리 2개가 다시 실행됐다.
불필요한 invalidation
상세 다이얼로그를 열 때마다 이런 코드가 실행되고 있었다:
useEffect(() => {
if (open) {
queryClient.invalidateQueries({ queryKey: ['dynamicItems'] });
}
}, [open]);
카드를 클릭할 때마다 전체 목록 쿼리를 강제 리페치한다. invalidateQueries는 staleTime을 무시하고 무조건 서버에 요청을 보낸다.
합산 효과
사용자 1명이 목록 페이지를 열면:
→ listItems (커넥션 1개, 30초 점유)
→ listDynamicItems (커넥션 1개, 30초 점유)
= 커넥션 2개 × 30초
사용자 3명 동시 접속:
= 커넥션 6개 × 30초
→ 풀 10개 중 6개 고갈 → 나머지 4개로 모든 요청 처리
→ 로그인 등 다른 endpoint 전부 대기 → 서버 먹통
풀 슬롯 시각화:
정상 운영 (사용자 1명, 60초 staleTime 적용 시)
[ ▓ ░ . . . . . . . . ] 1 ~ 2 slots, 빠른 회전
사고 직전 (사용자 3명, staleTime=0, 잦은 invalidate)
[ ░ ░ ░ ░ ░ ░ . . . . ] 6 slots 30초 점유 ← leak!
└──────┬───────┘
listItems × 3 + listDynamicItems × 3
남은 4 slot으로 로그인/조회 등 모든 요청 처리 → timeout 폭발
. idle ░ long (30s+)
로그의 6건 leak이 정확히 이 시나리오와 일치한다.
수정
// staleTime 추가 — 60초간 fresh 유지
const { data: dynamicItems } = useQuery({
queryKey: ['dynamicItems'],
queryFn: () => api.listDynamicItems(),
staleTime: 60_000,
});
// 다이얼로그 열 때 invalidation 제거
useEffect(() => {
if (open && item.type === 'PENDING_REVIEW') {
setExpandedUsers(new Set(item.subItems.map(s => s.userId)));
}
}, [open, item.type, item.subItems]);
사용자 자신의 액션(예약 완료, 상태 변경)은 여전히 invalidateQueries로 즉시 반영된다. staleTime은 “아무것도 안 했을 때의 자동 리페치”만 막는다.
한 달 전에 같은 걸 고쳤는데 왜 또 터졌나
한 달 전, 다른 도메인의 쿼리에서 동일한 dual collection FETCH JOIN 패턴을 발견하고 수정했다. 인사이트 문서까지 작성했다. 그런데 Task에 같은 패턴이 있었다는 건 이번 사고가 터질 때까지 몰랐다.
사고 후 전체 코드베이스를 감사했다. 58개 Repository의 모든 FETCH JOIN 쿼리를 검토한 결과, Task 외에 위험한 dual collection FETCH JOIN은 1건(QA 테스트 도구, 영향 없음)뿐이었다.
교훈은 명확하다: 안티패턴을 발견하면 해당 파일만 고치지 말고, 같은 패턴이 코드베이스 어디에 또 있는지 반드시 검색해야 한다. grep이면 충분하다.
# 같은 패턴이 또 있는지 확인
grep -r "JOIN FETCH" --include="*.java" src/ | \
awk -F: '{print $1}' | sort | uniq -c | sort -rn | \
awk '$1 > 2 {print}'
Before / After
배운 점
-
백엔드가 느리면 프론트엔드가 증폭한다. 1초 걸리는 쿼리는 staleTime 0이어도 별 문제 없다. 30초 걸리는 쿼리에 staleTime 0이면 커넥션 풀이 터진다. 프론트엔드 캐싱 전략은 백엔드 쿼리 성능과 함께 설계해야 한다.
-
안티패턴 발견 = 전수 감사. “이 파일 고쳤으니 끝”이 아니다. 같은 팀, 같은 코드베이스에서 같은 실수가 다른 곳에 있을 확률은 매우 높다.
-
Correlated subquery in SELECT는 보이지 않는 N+1이다. 애플리케이션 레벨에서는 쿼리 1개로 보이지만, DB 내부에서는 행 수만큼 서브쿼리가 실행된다. EXPLAIN으로 확인하거나 의심되면 배치 조회로 분리한다.
-
invalidateQueries는staleTime을 우회한다. React Query에서 staleTime을 아무리 길게 잡아도,invalidateQueries가 호출되면 즉시 리페치한다. 읽기 전용 화면에서 불필요한 invalidation이 없는지 점검해야 한다.
Comments