도입
AI에게 “이 메서드 쓰는 곳 다 찾아줘”라고 말하면, 뒤에서 무슨 일이 벌어질까?
바이브 코딩을 하면서 Serena MCP를 쓰고 있었다. 설치하고, 연결하고, 잘 되니까 그냥 썼다. 그런데 어느 날 연결이 안 되면서 삽질을 하다가, 이 도구 안에 컴파일러 이론의 핵심 개념들이 들어가 있다는 걸 알게 됐다.
이 글은 Serena의 설치법이나 기능 소개가 아니다. “이게 내부에서 뭘 하는 건지”를 비전공자도 이해할 수 있게 풀어본 글이다.
배경: AI는 코드를 어떻게 읽는가
AI에게 “이 함수 찾아줘”라고 하면, 어떻게 찾을까? 가장 단순한 방법은 Ctrl+F와 같다. 파일을 열어서 텍스트를 검색하는 것이다.
grep -r "findById" ./src
“findById”라는 글자가 포함된 모든 줄을 찾아준다. 간단하고 직관적이다. 하지만 문제가 있다.
텍스트 검색의 한계
도서관에서 “사과”라는 단어가 들어간 책을 찾는다고 생각해보자. Ctrl+F 방식은 모든 책의 모든 페이지를 넘기면서 “사과”라는 글자를 찾는 것이다. 그러면 이런 것들이 다 잡힌다:
- “사과나무가 열매를 맺었다” (원하던 것)
- “그는 진심으로 사과했다” (이건 아닌데…)
- “각주: 사과의 학명은 Malus domestica” (이것도 아닌데…)
코드에서도 같은 일이 벌어진다:
"findById" 검색 결과:
✅ taskRepository.findById(id) ← 이걸 찾고 싶었다
❌ findByIdResult = ... ← 변수명이 걸림
❌ // findById는 deprecated ← 주석이 걸림
❌ "findById" ← 문자열이 걸림
그리고 더 큰 문제가 있다. 토큰 소모다.
토큰이 왜 닳는가
AI 코딩 도구(Claude, Cursor 등)에는 “컨텍스트 윈도우”라는 게 있다. 쉽게 말하면 AI의 단기 기억 용량이다. AI가 코드를 읽으면 이 용량이 차고, 다 차면 더 이상 읽을 수 없다.
텍스트 검색 방식에서는 “save 메서드 하나만 보고 싶어”라고 해도 파일 전체를 읽어야 한다. 500줄짜리 파일에서 5줄짜리 메서드 하나를 보려고 500줄을 전부 기억 용량에 넣는 것이다.
500줄 파일에서 5줄짜리 메서드를 찾기 위해
→ 500줄 전부 읽음
→ 토큰 약 2,000개 소모
→ 이런 파일 10개만 읽으면 20,000 토큰
→ 토큰이 빠르게 닳는다
위 채팅에서 친구가 “3번 돌리고 끝났을 듯”이라고 한 게 바로 이 문제다. AI가 코드를 읽을 때마다 토큰이 닳고, 토큰이 다 떨어지면 더 이상 대화를 할 수 없다.
Serena가 다르게 하는 것: 코드를 “구조”로 읽기
다시 도서관 비유로 돌아가자.

텍스트 검색(grep)은 모든 책의 모든 페이지를 넘기는 것이다. 반면 Serena는 목차와 색인을 보는 것이다.
도서관 사서에게 “사과에 대한 내용 찾아주세요”라고 하면, 좋은 사서는 모든 책을 처음부터 읽지 않는다. 목차를 보고, “3장 과일류 → 3.2 사과” 항목을 찾아서 해당 페이지만 펼친다. 이게 Serena가 하는 일이다.
이걸 가능하게 하는 기술이 AST(Abstract Syntax Tree)와 tree-sitter다.
AST: 코드의 목차를 만드는 것
AST는 한국어로 “추상 구문 트리”인데, 이름이 어려워서 그렇지 원리는 단순하다. 코드를 계층 구조로 정리한 것이다.
이런 코드가 있다고 하자:
public void save(Task task) {
repository.save(task);
}
사람 눈에는 그냥 텍스트다. 하지만 AST로 변환하면 이런 구조가 된다:
메서드 선언
├── 접근자: public
├── 반환 타입: void
├── 이름: save
├── 파라미터:
│ └── Task 타입의 task
└── 본문:
└── repository의 save를 호출 (인수: task)
책에 비유하면 이렇다:
텍스트로 보기: "오늘은 날씨가 좋아서 산에 갔다..." (본문 전체를 읽어야 뭔 내용인지 앎)
AST로 보기: 3장 > 3.2절 > 등산 이야기 (목차만 보면 어디에 뭐가 있는지 앎)
이 “목차”가 있으면 파일 전체를 읽지 않아도 원하는 메서드만 바로 찾을 수 있다. 그래서 토큰이 절약된다.
tree-sitter: 목차를 순식간에 만드는 기계
AST(목차)를 만들려면 코드를 분석해야 한다. 이 분석을 해주는 도구가 tree-sitter다.
tree-sitter는 코드를 읽고 구조를 파악하는 프로그램이다. “이 중괄호는 클래스의 시작이고, 저 중괄호는 메서드의 끝” 같은 걸 이해한다. Rust라는 빠른 언어로 만들어져서 수천 줄의 코드도 순식간에 분석한다.
핵심 특징 세 가지:
1. 부분 업데이트: 코드 한 줄이 바뀌면 전체를 다시 분석하는 게 아니라, 바뀐 부분만 다시 분석한다. 500줄 파일에서 1줄만 고쳤으면 1줄만 다시 보는 것이다.
2. 오타에 강하다: 코드에 문법 오류가 있어도 최대한 분석해준다. IDE에서 코딩 중에 자동완성이 되는 것도 이 원리다 — 코드가 아직 완성되지 않았는데도 구조를 이해하고 있다.
3. 미리 인덱싱 안 함: IntelliJ나 VS Code는 프로젝트를 열면 “인덱싱 중…” 하면서 한참 기다리게 한다. tree-sitter는 그런 거 없이, 필요한 파일을 그때그때 즉시 분석한다.
왜 Ctrl+F로는 안 되는가 (CS 이론 한 줄)
“그냥 Ctrl+F 잘하면 되지 않나?” 할 수 있다. 근데 코드에는 중첩 구조가 있다. 클래스 안에 메서드가 있고, 메서드 안에 if문이 있고, if문 안에 또 메서드 호출이 있다.
class Service {
void process() {
if (condition) {
helper.save(data); // ← 이 save는 helper의 것
}
}
void save(Task task) { // ← 이 save는 Service의 것
repository.save(task); // ← 이 save는 repository의 것
}
}
“save”를 텍스트로 검색하면 3개가 다 잡히지만, 각각 다른 객체의 다른 메서드다. 이 차이를 이해하려면 “어떤 중괄호 안에 있는지”를 추적해야 하는데, 단순 텍스트 검색으로는 불가능하다. 이게 CS에서 말하는 “정규 언어의 한계”다 — Ctrl+F(정규식)로는 괄호의 중첩을 추적할 수 없고, 구조를 이해하는 파서가 필요하다.
그래서 뭐가 좋은데?
1. 토큰 절약 — 핵심 장점
500줄짜리 Java 파일에서 save 메서드 하나만 보고 싶을 때:
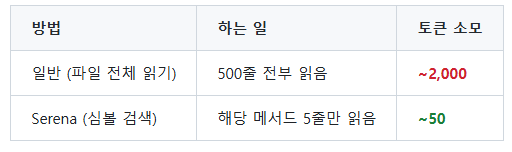


40배 차이. 하나의 작업에서 이런 파일을 10개, 20개 읽는다. 일반 방식으로 20개 파일을 읽으면 40,000 토큰이 닳지만, Serena로는 1,000 토큰이면 된다. 이 차이가 “3번 돌리고 끝” vs “하루 종일 작업 가능”의 차이다.
실제로 커뮤니티에서 보고된 토큰 절약률은 50~90% 범위다. Serena의 경량 버전인 serena-slim은 Serena의 도구 설명(tool description) 자체도 줄여서 50.3%의 추가 절약을 달성했다. 다만 이 수치들은 대부분 체감 기반이고, 동일 작업에 대한 정밀한 A/B 테스트 결과는 아직 공개된 것이 없다.
2. 정확한 참조 추적
“이 메서드를 호출하는 곳”을 찾을 때:
텍스트 검색: "save" → 변수명, 주석, 다른 클래스의 save까지 전부 잡힘 → 하나하나 확인 필요
Serena: "TaskService의 save" → 정확히 그 메서드를 호출하는 곳만 반환
결과가 정확하니까 AI가 “이건 관련 없고… 이것도 아니고…” 하면서 토큰을 쓸 필요가 없다.
3. 안전한 리팩토링
메서드 이름을 바꿀 때:
- 텍스트 치환: “save”를 “store”로 바꾸면 → 관련 없는 다른 save까지 다 바뀔 위험
- Serena: “TaskService.save”만 정확하게 “TaskService.store”로 변경
이건 IntelliJ나 VS Code에서 Shift+F6 (Rename Symbol) 하는 것과 같은 원리다. IDE도 내부적으로 AST를 사용한다. Serena는 그 능력을 AI 코딩 도구에 가져다준 것이다.
컴파일러와의 관계
여기까지 읽으면 “AST, 파서… 어디서 들어본 것 같은데?” 할 수 있다. 맞다. 컴파일러에서 쓰는 기술이다.
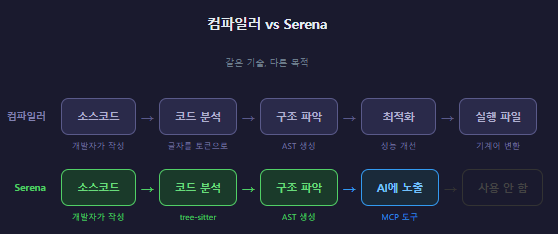
컴파일러는 코드를 컴퓨터가 실행할 수 있는 형태로 바꿔주는 프로그램이다. 그 과정은 이렇다:
소스코드 → [1단계: 코드 분석] → [2단계: 구조 파악] → [3단계: 최적화] → 실행 파일
읽기 AST 만들기 기계어 변환
Serena는 이 중 1~2단계만 가져다 쓴다. 코드를 분석하고 구조를 파악하는 것까지만 하고, 그 결과를 AI가 쿼리할 수 있게 도구로 노출한다. 컴파일은 안 하지만, 코드를 이해하는 능력은 컴파일러와 같다.
대학 컴퓨터공학과에서 “컴파일러”, “형식 언어” 같은 수업에서 배우는 내용이 바로 이것이다. 바이브 코딩을 할 때 의식하지 않지만, 뒤에서 이 이론이 돌아가고 있었다.
실전 삽질기: Windows에서 Serena가 안 될 때
Serena는 내부적으로 uvx라는 도구로 실행된다. uvx는 Python의 npx 같은 것으로, 패키지를 임시 환경에 설치하고 바로 실행한다.
문제는 Windows 11의 Smart App Control(SAC)이 uvx.exe를 차단한다는 것이다.
error: 애플리케이션 제어 정책에서 이 파일을 차단했습니다. (os error 4551)
원인: uv.exe/uvx.exe에 코드 서명이 되어 있지 않다. astral-sh/uv#18967에 이슈가 올라와 있고, 아직 해결되지 않았다 (2026년 4월 기준).
해결 방법
Smart App Control을 끄는 수밖에 없다:
- Windows 보안 → 앱 및 브라우저 컨트롤 → Smart App Control → 끄기
- 주의: 한번 끄면 다시 켤 수 없다 (Windows 재설치 필요)
SAC를 꺼도 Windows Defender와 SmartScreen은 그대로 동작하므로, 실질적인 보안 위험은 낮다. 다만 서명되지 않은 실행 파일에 대한 추가 보호막이 사라지는 것이므로, 수상한 exe를 직접 다운받아 실행하지 않는 습관이 중요하다.
winget으로 설치해도 바이너리 자체가 unsigned라 차단된다. uv 측에서 코드 서명을 추가할 때까지는 SAC 환경에서 Serena를 쓸 수 없다.
배운 점
-
바이브 코딩 도구도 결국 CS 기초 위에 서 있다. AST, 파서, 형식 언어 이론 — 이런 것들이 “쓸모없는 이론”이 아니라 실제로 매일 쓰는 도구의 핵심이다.
-
텍스트 검색과 구조적 검색은 차원이 다르다. grep으로 충분하다고 생각했는데, 토큰 효율과 정확도에서 비교가 안 된다.
-
도구가 안 될 때 원리를 알면 디버깅이 된다. “Serena가 안 돼요” → uvx → uv → 코드 서명 → Smart App Control. 원리를 모르면 “재설치” 밖에 할 수 없다.
다음 글 예고
“50~90% 절약”이라는 커뮤니티 수치는 체감 기반이다. 그래서 직접 실험해보려 한다. 동일한 작업을 Serena ON/OFF로 실행하고, 실제 토큰 소모량을 측정하는 A/B 테스트. 결과가 나오면 후속 글로 공유할 예정이다.
Comments