
Intro
AI writes pretty good code. And yet features with many branches keep getting tangled. You say “build this,” the first cut looks plausible, it breaks at an edge, you patch it, the patch breaks another branch, and somewhere along the way the original intent blurs.
Building one such heavily-branched feature with AI, at some point I stopped writing code and laid out every case as a single matrix first. The tangling stopped. This post is the three devices I used. Up front: lean on AI’s strengths (exhaustiveness, speed), and contain its weaknesses (hallucination, “looks done”) with the structure of the workflow.
Why it tangles
Abstractly, the feature was this: change an object’s “type,” and depending on the new type a state transition in another domain has to follow. Flip an item to a “transition-start” type and the transition begins; if one is already in progress, link to it; if a value exists, move it; the opposite direction releases it — and so on.
The core problem is that you discover these branches while writing the code. AI writes the happy path fast, but a branch like “an object that already went through once and still has a stale record” gets hit mid-implementation, or never. When a human finds them one by one in review and patches — the patch touches yet another branch. The classic “repeated patching = a sign of a missing design.”
1. Build the “full case matrix” before code
The key shift was freezing every branch on one page before writing code. But I didn’t try to draw the perfect matrix in one shot (that’s its own fantasy). I converged toward it in stages:
- Compare design options — put the type-change control UI as option A vs. B side by side, pick one.
- Change matrix + guards — formalize which type → which type is allowed/blocked as a table.
- Behavior orchestration — the flow of what happens when you switch to a transition type.
- Exhaustive case spec — synthesize the above into a single matrix with no empty cells. Add a comment per case, run two rounds, and freeze the wording and behavior.
The matrix that came out looked like this (domain-generalized):
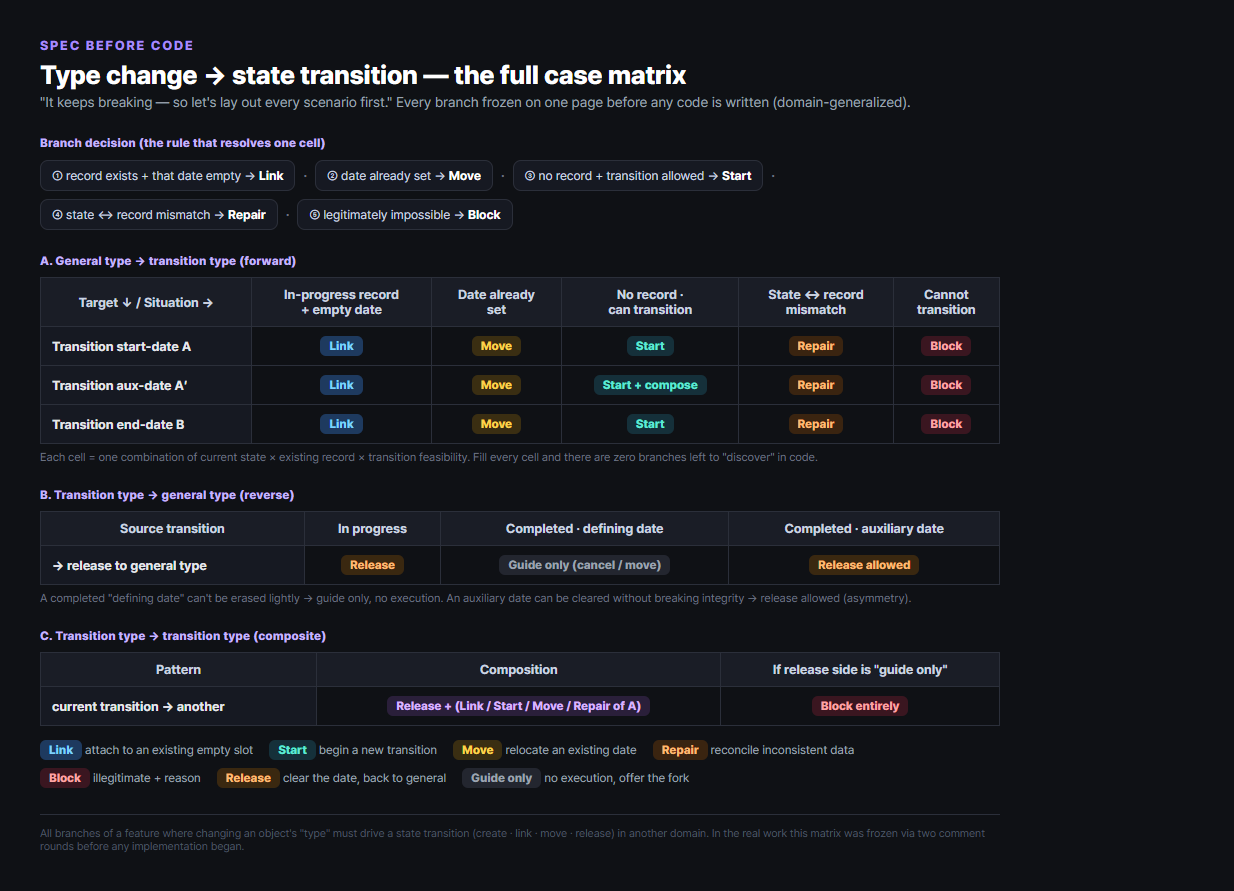
The full set of branches for a feature where “changing a type drives a state transition.” Forward (general → transition) splits into Link/Move/Start/Repair/Block by current state × existing record × feasibility; reverse (transition → general) splits into Release/Guide by in-progress vs. completed; transition↔transition is a composition of the two.
The figure above is actually a simplified slice. The spec we really froze was far bigger — changes split into three families (forward, reverse, and transition↔transition composite), filling ~20 cases with no empty cell, each cell further resolved by current state × existing record × feasibility. So one “change the type” action resolved into 13 distinct outcomes — link, start, move, repair, block, release, plus 5 composite ones for when a reverse-release overlaps a forward action. execute re-judges the branch preview chose and rejects it if the state shifted in between (a race guard), and this judgment logic alone is pinned by 44 tests.
That matrix became the contract. AI implements against the frozen table; the human reviews against the same table. You don’t ask “how should this case behave?” during code review — it’s already written in the cell.
This makes the human/AI division clear. Enumerating the cases and writing the code is AI’s job; deciding each cell’s domain meaning is the human’s. AI is strong at “list every combination you can think of,” the human at “this cell like so, block that one.” The human fills the cells — but AI is what surfaces where the cells are.
Compare options → formalize rules → define behavior → freeze all cases. Not drawing the answer in one shot, but narrowing in stages so nothing is missing at the end.
2. Review twice — independent and adversarial
After implementation I ran review twice, independently.
- First pass: sweep the changed code from four fixed angles (correctness / conventions / security & edges / completeness).
- Second pass: in a separate, clean context, take the first pass’s conclusions as input and run it with an explicit instruction to “refute this.”
Run the same review twice in the same context and the same anchoring yields the same conclusions. So the second pass deliberately isolates context and is set up adversarially. The result was telling — the second pass overturned 2 of the 4 findings (first pass + its own).
- One flagged “this delete path also wipes related data” as a risk — but the actual implementation was a soft-delete, not a hard delete, so related data was preserved. A false risk from assuming framework behavior.
- Another said “this time conversion doesn’t pin a timezone, risky” — but it matched the codebase’s existing canonical pattern. Changing only my code would have created the inconsistency.
Two lessons. First, AI review also hallucinates. “The framework probably behaves like X,” filed as a finding without verification, becomes a false positive — so findings that lean on framework behavior must be verified against source/docs before reporting. Second, don’t surrender the moment you’re refuted. When questioned, re-verify the basis; if wrong, say exactly where and retract; if right, give the basis and hold. AI tends to reflexively collapse into “sorry, I was wrong” when a user expresses doubt — and that erodes the review’s trustworthiness.
3. “Code exists ≠ it works” — reachability check
The last one paid off most. Implementation, review, and tests all passed — but clicking through the real screen end to end revealed two things.
- A reverse branch was unreachable. The dialog and logic code were sitting there intact, but upper-level routing intercepted the click and opened a different screen. The UI I built had no path into it. Reading the code won’t catch this — the component exists.
- One cell agreed in the matrix wasn’t implemented at all. The entry UI that turns that case on was simply missing. “Agreed in the matrix ≠ implemented.”
Neither is caught by unit tests (they call functions directly, so they don’t verify “reachability”), nor by code review (the code is all there). Only an e2e that walks the real usage path to the end surfaces them.
This isn’t new — where it sits
None of the three devices are inventions. They’re existing things, recombined and made concrete for a solo + AI loop.
- #1 (matrix before code) is a form of Spec-Driven Development, hot in 2026 (the spec is the single source of truth, “stop the drift of vibe coding”). What I added is the converging mockup sequence and freezing the spec as a decision table. A decision table is a 40-year-old black-box testing technique that enumerates condition combinations exhaustively — here it’s pulled forward into a design-time artifact, with AI enumerating and the human deciding each cell. (Few enough conditions made a full matrix feasible; larger, and you’d need combinatorial reduction like pairwise.)
- #2 (adversarial second review) is the same grain as the active research on multi-agent adversarial debate/voting to cut LLM hallucination and false positives (AI code-review hallucination is empirically flagged, too). Instead of a grand N-agent vote, it’s a lightweight version: one independent second reviewer refuting the first.
- #3 (reachability check) is no new technique — it’s a re-confirmation of the old truth that “passing tests and review” doesn’t guarantee “the user reaches the feature.”
In short, SDD + decision tables + adversarial review, woven into a small loop one person runs with AI.
Takeaways
The three devices ultimately move where human supervision sits in AI collaboration.
- Put the spec (matrix) before the code and converge it — branch decisions happen at the matrix stage, by a human, not in code review.
- Review once more, independent and adversarial — assume AI review hallucinates, and answer refutation with evidence.
- Verify “done” by real reachability, not by code — by the user’s path, not by a component’s existence.
This isn’t “AI did it well.” AI’s exhaustiveness and speed are used as-is, while its two weaknesses — hallucination and “looks done” — are contained by the structure of the workflow. Human supervision moves from reviewing code line by line to agreeing on the matrix, refuting the review, and confirming reachability. The cheaper code gets, the more that seat matters.
References
- Spec-Driven Development with AI Coding Agents (2026) · SDD: The 2026 Guide (BCMS)
- Decision Table Testing (ZetCode) · Decision Table Based Testing (GeeksforGeeks)
- Adversarial debate & voting to reduce LLM hallucinations (MDPI, 2025) · adversarial-review (GitHub) · LLM hallucinations in AI code review (diffray)
- Kent Beck, “Make the change easy, then make the easy change”
Comments