학원 관리 시스템을 개발하면서, 학생 상태 뱃지를 클릭했을 때 팝오버가 1초간 빈 흰 박스로 보이는 UX 문제를 발견했다. 단순한 프론트엔드 로딩 처리 누락으로 시작한 조사가, 서버 전체 56개 Response DTO를 감사하고 4건의 CRITICAL한 N+1 문제를 수정하는 작업으로 확장된 이야기다.
이 글에서는 다음을 다룬다:
- 프론트엔드 UX 문제에서 서버 쿼리 문제를 추적하는 과정
- JPA LAZY Loading이 Response DTO 변환에서 N+1을 일으키는 패턴
- 전체 프로젝트 감사 방법과 결과
- Hibernate Statistics를 활용한 쿼리 카운트 회귀 테스트
문제 발견
학생 목록에서 상태 뱃지(등록예정, 재원 등)를 클릭하면 팝오버가 열리면서 등퇴원 관련 정보를 보여준다. 그런데 클릭 후 약 1초간 아무 내용 없는 빈 흰 박스가 표시되고 있었다.

이 팝오버는 의도적으로 lazy fetch 방식을 사용하고 있었다. 학생 목록에서 학생 수만큼 API를 호출하면 N+1 문제가 생기니까, 팝오버를 열 때만 해당 학생의 등퇴원 기록을 가져오는 것이다. 합리적인 설계였지만, 부작용으로 로딩 중 빈 UI가 노출되는 문제가 있었다.
1단계: 프론트엔드 즉각 대응
가장 먼저 빈 박스 문제를 해결했다. 두 가지를 적용했다.
로딩 스피너 추가: 데이터를 가져오는 동안 빈 박스 대신 스피너를 보여준다.
{isLoadingRecord && (
<div className="flex items-center justify-center py-3">
<Loader2 className="h-5 w-5 animate-spin text-gray-400" />
</div>
)}
hover prefetch: 마우스를 올리는 순간 데이터를 미리 요청한다. 클릭할 때쯤(~200-500ms 후) 이미 캐시에 데이터가 있으므로 팝오버가 즉시 렌더링된다.
const handleMouseEnter = useCallback(() => {
if (isPending) {
prefetchEnrollmentRecordsByUser(queryClient, studentId);
}
}, [isPending, queryClient, studentId]);
export const prefetchEnrollmentRecordsByUser = (
queryClient: QueryClient, userId: number
) => {
queryClient.prefetchQuery({
queryKey: enrollmentKeys.byUser(userId),
queryFn: () => api.getRecordsByUser(userId),
staleTime: 30_000, // 30초 내 재hover 시 중복 요청 방지
});
};
staleTime: 30_000을 설정하여 30초 내에 같은 학생 위에 마우스를 다시 올려도 중복 요청이 발생하지 않는다.
2단계: 서버 쿼리 분석
프론트엔드는 해결했지만, 서버에서도 실제 응답 시간을 줄일 수 있는지 확인했다.
해당 API의 서버 코드를 보니:
public List<TransitionResponse> getTransitionsByUserId(Long targetUserId) {
StudentCampusProfile scp = scpRepository
.findByUserIdAndCampusId(targetUserId, campusId)
.orElseThrow(...);
return transitionRepository
.findByScpIdOrderByCreatedAtDesc(scp.getId())
.stream()
.map(TransitionResponse::from) // 여기서 문제 발생
.collect(Collectors.toList());
}
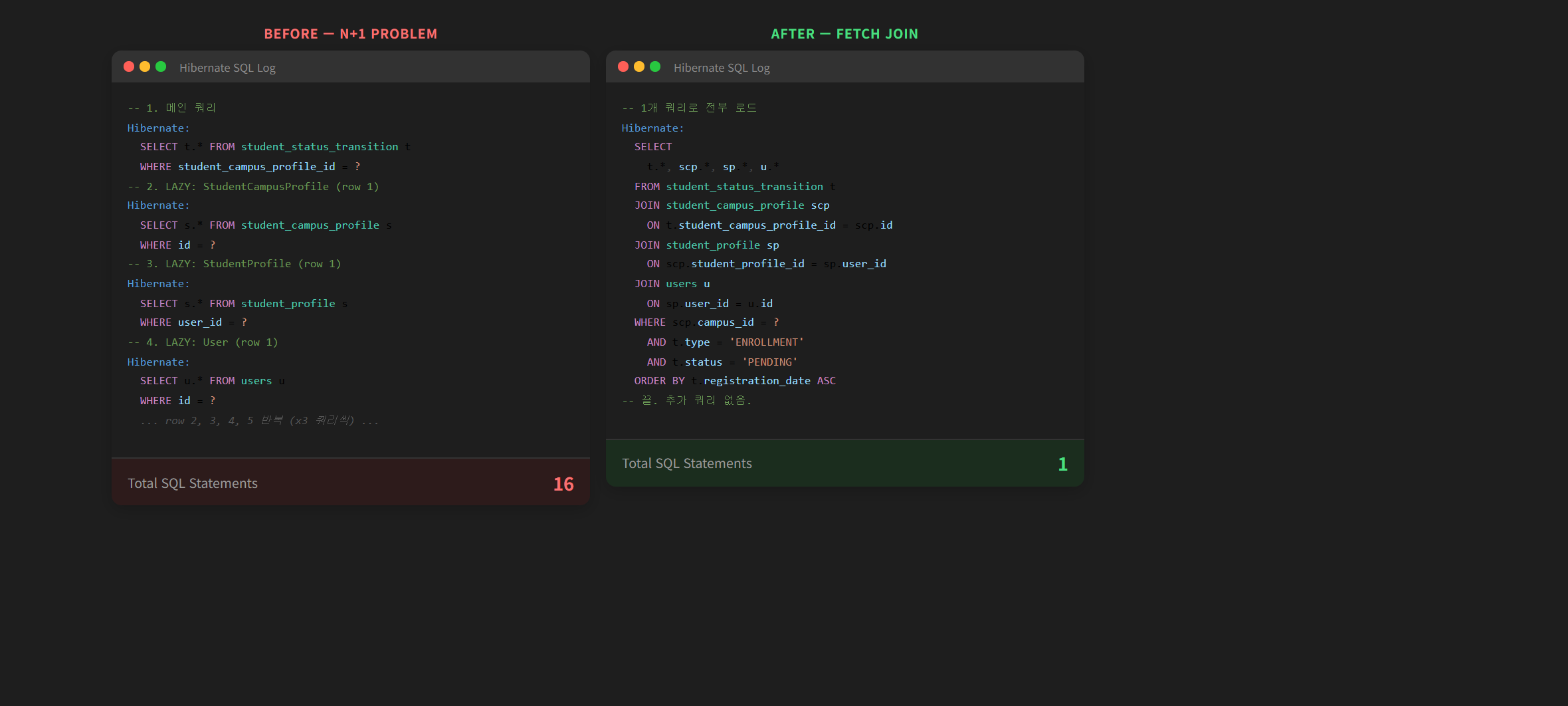
findByScpIdOrderByCreatedAtDesc는 Spring Data JPA의 derived query로, FETCH JOIN이 없다. 그런데 TransitionResponse.from()에서는:
public static TransitionResponse from(Transition transition) {
// LAZY 연관 접근 → 추가 쿼리 발생!
var scp = transition.getStudentCampusProfile(); // 쿼리 1
var sp = scp.getStudentProfile(); // 쿼리 2
var user = sp.getUser(); // 쿼리 3
builder.studentName(user.getName());
}
Transition → StudentCampusProfile → StudentProfile → User까지 3단계 LAZY 연관을 순차적으로 접근하고 있었다. 데이터가 N건이면 최대 3N개의 추가 쿼리가 발생한다.
3단계: FETCH JOIN 적용
해결은 간단하다. Repository 쿼리에 FETCH JOIN을 추가하면 된다.
// Before: derived query (FETCH JOIN 없음)
List<Transition> findByScpIdOrderByCreatedAtDesc(Long scpId);
// After: FETCH JOIN으로 연관 엔티티까지 한 번에 로드
@Query("SELECT t FROM Transition t " +
"JOIN FETCH t.studentCampusProfile scp " +
"JOIN FETCH scp.studentProfile sp " +
"JOIN FETCH sp.user " +
"WHERE scp.id = :scpId " +
"ORDER BY t.createdAt DESC")
List<Transition> findByScpIdWithProfileOrderByCreatedAtDesc(
@Param("scpId") Long scpId);
4단계: 전체 프로젝트 감사
이 패턴이 다른 곳에서도 발생하고 있을 가능성이 높았다. 프로젝트 전체 56개 Response DTO의 from() 메서드를 감사했다.
감사 기준:
- Response DTO에
from()/toDto()등 변환 메서드가 있는가? - 그 메서드에서 LAZY 연관(
@ManyToOne(fetch = LAZY)등)을 접근하는가? - 호출부의 Repository 쿼리가 해당 연관에 FETCH JOIN을 사용하는가?
결과: CRITICAL 4건 발견
| Response DTO | LAZY 접근 체인 | 수정 전 (5건) | 수정 후 |
|---|---|---|---|
| WaitingRequestResponse | SCP → StudentProfile → User | 17 | 1 |
| TransitionResponse | SCP → StudentProfile → User | 16 | 1 |
| InquiryResponse | targets(OneToMany) → User, Campus | 17 | 7 |
| SeatReservationResponse | SeatGroup → Room, User, NextUser | 8 | 1 |
InquiryResponse가 1이 아닌 7인 이유는 @OneToMany 컬렉션(targets)의 특성 때문이다. 컬렉션 FETCH JOIN은 메인 쿼리 1개로 완전히 해결되지 않는 경우가 있다. 그래도 17 → 7로 크게 개선되었다.
5단계: 회귀 방지 테스트
FETCH JOIN을 추가했다고 끝이 아니다. 누군가 나중에 쿼리를 수정하면서 FETCH JOIN을 빼먹을 수 있다. Hibernate의 Statistics를 활용한 쿼리 카운트 테스트를 작성했다.
@DataJpaTest
@ActiveProfiles("test")
class FetchJoinQueryCountTest {
private Statistics statistics;
@BeforeEach
void setUp() {
EntityManager em = testEntityManager.getEntityManager();
SessionFactory sf = em.unwrap(Session.class).getSessionFactory();
statistics = sf.getStatistics();
statistics.setStatisticsEnabled(true);
}
@Test
void waitingRequest_findActiveByClassId_singleQuery() {
// Given: 3명의 학생이 대기 중
// ... 테스트 데이터 생성 ...
testEntityManager.flush();
testEntityManager.clear(); // 1차 캐시 비움
statistics.clear(); // 카운터 리셋
// When: Repository 쿼리 실행 + LAZY 연관 접근
List<WaitingRequest> results = repository.findActiveByClassId(classId);
results.forEach(wr -> {
wr.getProfile().getStudentProfile().getUser().getName();
});
// Then: FETCH JOIN이므로 1개 쿼리만 실행
assertThat(statistics.getPrepareStatementCount()).isEqualTo(1);
}
}
핵심 포인트:
statistics.clear()전에 반드시entityManager.clear()로 1차 캐시를 비워야 한다. 그렇지 않으면 캐시에서 엔티티를 가져와서 쿼리가 안 나간다.getQueryExecutionCount()가 아닌getPrepareStatementCount()를 사용해야 한다. 전자는 JPQL 실행만 카운트하고, lazy loading으로 발생하는 SQL은 잡지 못한다.application-test.yml에hibernate.generate_statistics: true설정이 필요하다.
결과
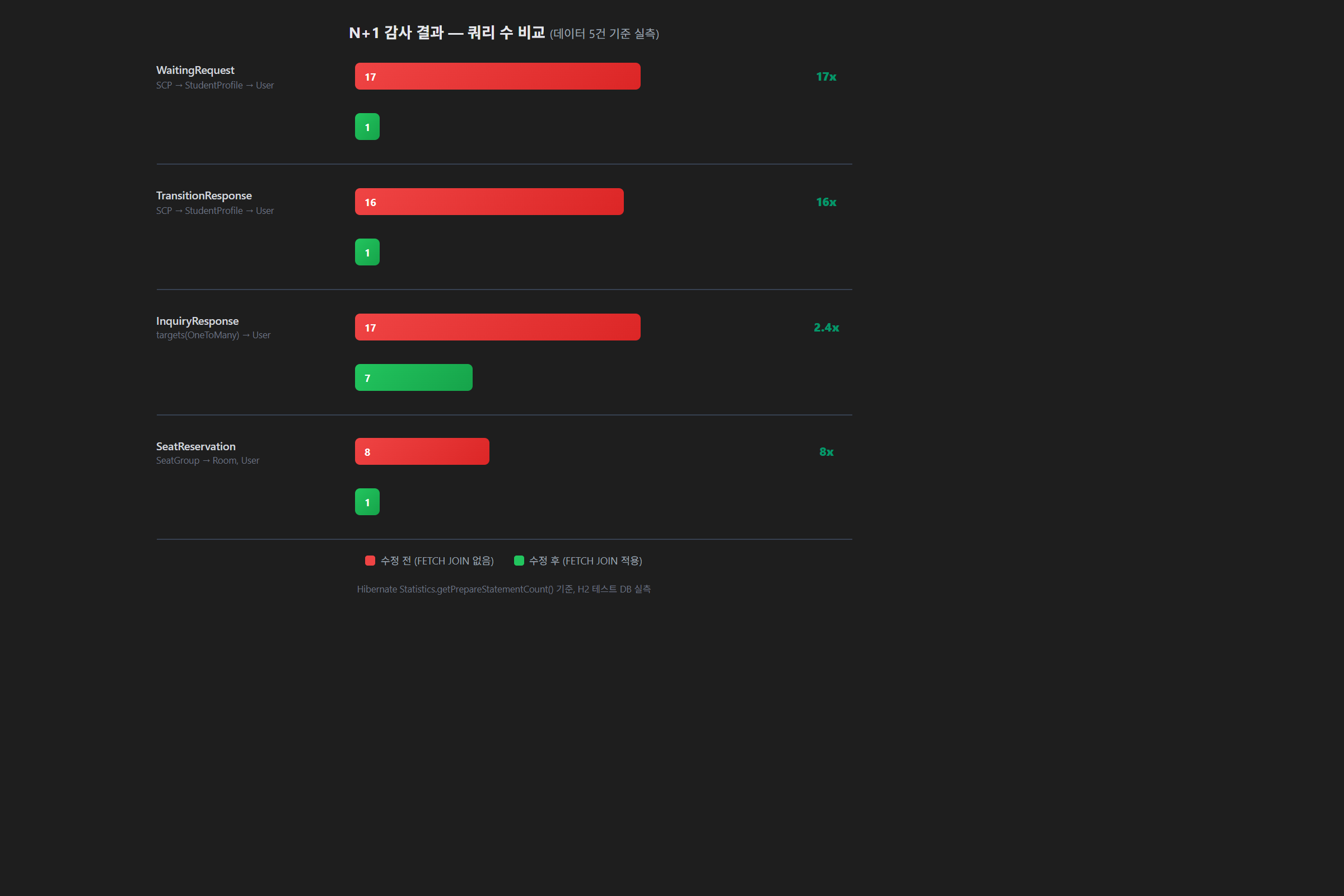
| 대상 | 수정 전 | 수정 후 | 절감률 |
|---|---|---|---|
| WaitingRequest | 17 queries | 1 query | 17x |
| Transition | 16 queries | 1 query | 16x |
| Inquiry | 17 queries | 7 queries | 2.4x |
| Seat | 8 queries | 1 query | 8x |
데이터가 늘어날수록 차이는 더 벌어진다. 대기 학생이 30명이면 수정 전에는 약 100개의 쿼리가 나갔을 것이다.
정성적 개선:
- UX: 팝오버 빈 박스 → 즉시 렌더링 (hover prefetch)
- 규칙화: 코딩 규칙에 “LAZY Loading N+1 Prevention” 룰 추가 → 향후 코드 작성 시 자동 적용
- 회귀 방지: 쿼리 카운트 테스트 → FETCH JOIN 누락 시 CI에서 즉시 감지
Lessons Learned
1. UX 문제 뒤에 서버 문제가 숨어 있을 수 있다
“로딩이 느려요”라는 피드백은 프론트엔드 문제일 수도, 서버 문제일 수도 있다. 이번엔 프론트 + 서버 양쪽 모두 개선 포인트가 있었다. 한쪽만 보면 절반만 해결된다.
2. derived query의 함정
Spring Data JPA의 derived query(findByXxxOrderByYyy)는 편리하지만, FETCH JOIN을 지원하지 않는다. DTO 변환에서 LAZY 연관을 접근한다면 반드시 @Query로 FETCH JOIN을 명시해야 한다.
3. getPrepareStatementCount()를 써야 한다
Hibernate Statistics로 N+1을 검증할 때, getQueryExecutionCount()는 JPQL 실행만 카운트한다. lazy loading은 내부적으로 prepared statement로 실행되므로 getPrepareStatementCount()를 사용해야 정확한 수치를 얻을 수 있다. 이걸 모르면 “N+1이 없다”는 잘못된 결론을 내릴 수 있다.
4. 하나 발견하면 전체를 봐야 한다
한 곳에서 N+1 패턴이 발견되면, 같은 패턴이 다른 곳에도 있을 확률이 높다. 56개 DTO를 전수 감사한 결과 4건의 CRITICAL 이슈를 추가로 발견했다. 점검 기준을 규칙으로 만들어두면 앞으로 같은 실수를 방지할 수 있다.
Comments