
“매분 DB를 조회하는 폴링 방식, 과연 죄악일까?” “이벤트 기반 아키텍처는 언제나 옳은가?”
최근 알림 시스템을 고도화하면서 팀 내에서 치열하게 논의했던 ‘시간 기반 알림(Time-based Notification)’ 아키텍처 설계 과정을 공유합니다.
문제 상황
우리 시스템에는 다음과 같은 시간 기반 알림 요구사항이 있었습니다.
- Type A (정기 결제 안내): 매월 결제일 다음 날 09:00 발송
- Type B (일일 미션 미수행): 마감 당일 특정 시각 발송
- Type C (근무자 시작 알림): 근무 시작 10분 전 발송
- Type D (근무자 지각 알림): 근무 시작 5분 후 미출근 시 발송
이 요구사항을 구현하기 위해 두 가지 설계 옵션이 대립했습니다.
Round 1: 옵션 A(스케줄러) vs 옵션 B(이벤트 큐)
옵션 A: 전용 스케줄러 (Polling)
매분(또는 매일) 스케줄러가 돌아가며 조건을 만족하는 대상을 찾아 발송하는 방식입니다.
@Scheduled(fixedDelay = 60000)
public void checkLateWorkers() {
// 1. 현재 시각 기준 근무 시작 5분 지난 사람 조회
// 2. 아직 출근 안 한 사람 필터링
// 3. 알림 발송
}
- 장점: 구현이 단순하고, 데이터의 정합성(Consistency)이 보장됩니다. 실행 시점(Runtime)에 DB를 조회하므로 취소 누락 등의 상태 불일치 문제가 없습니다.
- 단점: “매분 DB를 찌른다”는 죄책감. 데이터 양이 많아지면 성능 이슈(Full Scan 등)가 생길 수 있습니다.
옵션 B: 이벤트 큐 (PendingNotification)
이벤트가 발생하는 시점(예: 스케줄 생성)에 미래의 알림을 미리 예약해두는 방식입니다.
// 스케줄 생성 시
pendingNotificationService.schedule(
userId,
"TYPE_D",
startTime.plusMinutes(5) // 발송 예약
);
- 장점: 정확한 시각에 트리거되므로 불필요한 조회가 없습니다. ‘이벤트 기반’이라는 멋진 아키텍처에 부합합니다.
- 단점: ‘상태 동기화(State Synchronization)’ 지옥.
- 스케줄이 바뀌면? → 예약 취소하고 다시 걸어야 함.
- 중간에 출근하면? → 예약 취소해야 함.
- 취소 로직 누락 시? → “출근했는데 왜 지각 알림 와요?” (오발송 장애)
Round 2: 상태 기반 vs 이벤트 기반 심층 분석
논의 중 “모든 알림을 하나로 볼 것이 아니라, 성격을 나눠야 한다”는 결정적인 인사이트가 나왔습니다.
이때 우리가 세운 판단 기준(Judgment Criteria)은 다음과 같습니다.
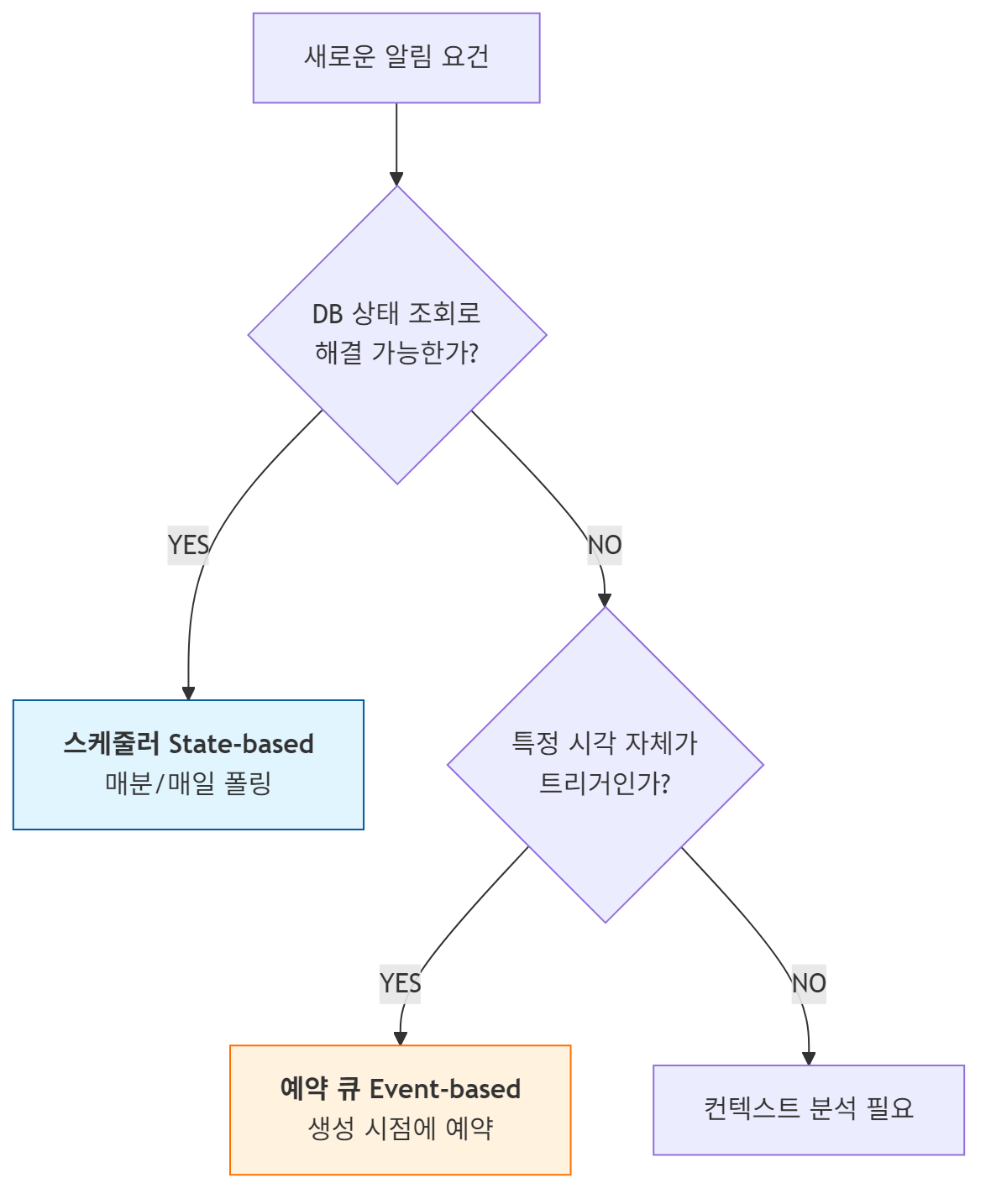
1. 상태 기반 (State-based) 알림
- 대상: 정기 결제(Type A), 미션 미수행(Type B)
- 특징: “언제”가 중요한 게 아니라 “지금 어떤 상태인가”가 중요합니다.
- 결론: 이건 스케줄러(Polling)가 맞습니다. 매일 아침 “결제 안 한 사람 누구?” 하고 조회하는 게 가장 깔끔합니다. 예약 걸었다가 납부하면 취소하는 로직은 불필요한 복잡도입니다.
2. 이벤트 기반 (Event-based) 알림
- 대상: 근무 시작 전(Type C), 지각(Type D)
- 특징: “근무 시작 시간”이라는 명확한 트리거 시점이 존재합니다.
- 결론: 아키텍처적으로는 이벤트 큐(Pending)가 맞습니다.
만약 이걸 스케줄러로 짠다면, 매분 이런 괴물 쿼리를 돌려야 합니다.
SELECT ws.* FROM work_schedules ws
WHERE ws.start_time - INTERVAL 10 MINUTE BETWEEN :now AND :now + 1min
AND NOT EXISTS (SELECT 1 FROM attendance_logs WHERE ...) -- 이미 출근했는지
AND NOT EXISTS (SELECT 1 FROM leave_requests WHERE ...) -- 휴가 중인지
반면, 이벤트 큐 방식을 쓰면 “생성 시점에 시간 계산 + 발송 시점에 조건 확인”으로 로직이 훨씬 깔끔해집니다.
Round 3: 이상(Ideal) vs 현실(Reality)
하지만 여기서 “현실적인 엔지니어링 비용” 문제가 제기되었습니다.
“이벤트 큐(Pending)가 아키텍처적으로 옳다는 건 인정해. 그런데 우리
PendingNotification테이블은 단순 배치용으로 설계돼 있잖아? 개별 예약/취소/수정을 지원하려면 인프라 공사부터 다시 해야 하는데?”
[Deep Dive] 자바 스케줄러는 어떻게 동작하나?
논의 중 가장 큰 오해는 “스케줄러가 매 초마다 시계를 쳐다보면서 CPU를 쓴다(Busy Waiting)”는 것이었습니다. 하지만 현대 OS와 자바는 그렇게 멍청하지 않습니다.
1. 택시 기사(Thread)와 배차 반장(Executor)
ThreadPoolTaskScheduler 내부에는 대기 중인 스레드(택시 기사)와 이들을 관리하는 큐(배차 반장)가 있습니다.
- 반장은 큐의 맨 앞에 있는 작업 시간(09:00)을 확인합니다.
- 지금이 08:50이라면, 반장은 “10분 뒤에 깨워줘”라고 OS에 알람을 요청하고 잠듭니다(Wait).
- 이때 스레드는
PARK상태가 되어 CPU 사용량이 ‘0’이 됩니다.
2. 하드웨어의 마법 (OS Timer Interrupt)
그렇다면 누가 깨워줄까요? 바로 컴퓨터의 심장(Clock)입니다.
- 메인보드의 수정 발진자(Quartz)가 1ms마다 전기 신호(Interrupt)를 OS에 보냅니다.
- OS는 이 신호를 받을 때만 잠깐 일어나서 “깨울 애 있나?” 장부를 확인합니다.
- 09:00가 되면 OS가
Wait하고 있던 자바 스레드를 “일어나!” 하고 흔들어 깨웁니다(Notify).
결론: 스케줄러를 100개 등록해도, 실행 시간이 되기 전까지는 시스템 리소스를 전혀 잡아먹지 않습니다. “매분 폴링”에 대한 과도한 죄책감을 가질 필요가 없는 이유입니다.
자바 내부 스케줄러 vs DB 기반 큐
질문: “그냥 자바 메모리 스케줄러 쓰면 안 되나요?” 답변: 안 됩니다. 서버가 재시작되면 예약된 알림이 다 날아가기 때문입니다(휘발성). 상용 서비스에서는 반드시 DB 기반의 영속적(Persistent) 큐가 필요합니다.
결국 “제대로 된 DB 기반 예약 시스템(Quartz 등)을 구축할 것인가?” vs “지금 있는 스케줄러로 처리할 것인가?”의 싸움이 되었습니다.
최종 결론: 단계적 접근 (Phased Approach)
우리는 “실용주의(Pragmatism)”를 선택했습니다.
하이브리드 아키텍처 (Hybrid Architecture)

Phase 1: All Scheduler (지금 당장)
- 모든 알림(Type A, B, C, D)을 스케줄러 폴링으로 구현합니다.
- 이유:
- 현재 트래픽(단일 인스턴스)에서는 매분 폴링 부하가 ‘0’에 수렴합니다.
- 인프라 구축 없이 비즈니스 로직만 짜면 바로 배포 가능합니다.
- 데이터 정합성 면에서 가장 안전합니다. (Source of Truth = DB)
Phase 2: Hybrid (미래)
- 나중에 트래픽이 폭증하거나, 근태 데이터가 너무 많아져 폴링이 부담스러워지면?
- 그때 Type C, Type D만 떼어내어 고도화된 예약 시스템(Pending)으로 이관합니다.
[Comparison] 더 큰 물에서 노는 법 (대규모 트래픽)
만약 우리가 네이버나 카카오 규모였다면 어떻게 설계했을까요?
1. Kafka Delay Queue (대규모 이벤트 기반)
- 패턴: 메시지를 바로 컨슈머에게 주지 않고, 별도의 ‘Delay Topic’에 넣어둡니다.
- 원리: 컨슈머가 메시지를 읽을 때 타임스탬프를 확인하고, “아직 시간이 안 됐네?” 하면 다시 뒤로 미루거나 잠시 대기합니다.
- 장점: 엄청난 처리량(Throughput)과 확장성.
- 단점: 구현 복잡도가 매우 높습니다. (파티션 관리, 오프셋 커밋 등)
2. Redis Sorted Set Delay Queue (스타트업의 친구)
- 패턴: Redis의
ZSET자료구조를 활용합니다. - 명령어:
ZADD delay_queue <timestamp> <job_id> - 원리: 점수(Score)를 ‘발송 예정 시각(Unix Timestamp)’으로 잡고 저장합니다. 그리고 스케줄러가 1초마다
ZRANGEBYSCORE delay_queue 0 <now>를 날려서, 현재 시각보다 과거인 작업들을 쏙 뽑아옵니다. - 장점: 구현이 쉽고 매우 빠릅니다. DB 부하를 획기적으로 줄여줍니다.
- 단점: Redis가 터지면 예약된 알림이 날아갈 수 있습니다 (AOF/RDB 설정 필수).
우리 팀의 선택: 현재는 RDB(MySQL/PostgreSQL) 기반의
PendingNotification테이블로도 충분합니다. 인덱스만 잘 타면 수십만 건까지는 RDB가 가장 안전하고 관리하기 쉬운 큐입니다.
교훈 (Takeaway)
- “Simple is Best”: 복잡한 아키텍처(이벤트 기반)가 항상 정답은 아닙니다. 규모에 맞는 적정 기술을 선택하세요.
- Source of Truth: 알림 발송 직전에는 반드시 DB를 한 번 더 확인하세요. (Double Check)
- OS의 비밀: 스케줄러가 매분 돈다고 해서 CPU가 100% 도는 건 아닙니다. OS 타이머 인터럽트(Hardware Timer Interrupt)와 스레드 대기(Wait/Notify) 매커니즘 덕분에 대기 시간에는 자원을 거의 쓰지 않습니다.
결론: 아키텍처의 우아함보다 중요한 건 “지금 당장 작동하고, 안전하며, 유지보수 가능한가”입니다.
참고 문헌 (References)
- Polling vs Event-Driven:
- Understanding push vs poll in event-driven architectures - TheBurningMonk
- Event-Driven vs. Polling Architecture - Design Gurus
- When to use Polling vs Webhooks - Zapier Engineering
- Java Scheduler Internals:
Comments