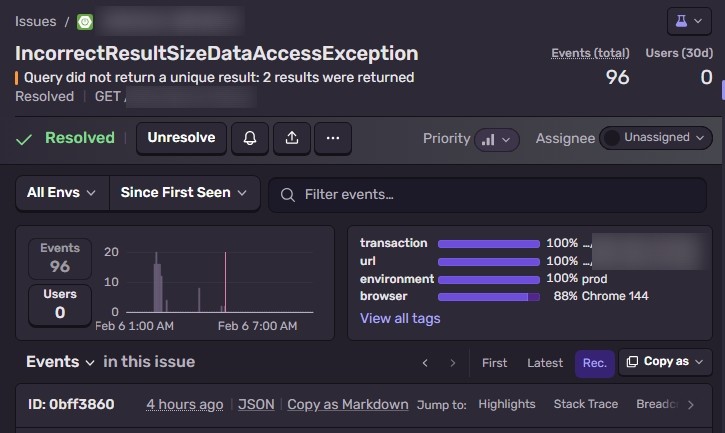
오전 11시, Sentry에서 알림이 왔다.
NonUniqueResultException: Query did not return a unique result: 2 results were returned
96회. 그것도 escalating. 예약 현황 대시보드가 통째로 먹통이 됐다. 현황 API(GET /rooms/status)에서 터진 거였다.
Sentry가 잡아준 스택트레이스를 따라가보면, findCurrentRoomBooking이라는 JPA 쿼리가 범인이다. Optional<RoomBooking>으로 선언된 — 즉 결과가 0 또는 1개여야 하는 — 쿼리가 2개를 반환하면서 터졌다.
단일 결과를 기대하는 쿼리가 2개를 반환했다는 건, DB에 있으면 안 되는 중복 데이터가 있다는 뜻이다. 이건 단순한 쿼리 에러가 아니라, “같은 회의실에 겹치는 예약은 존재할 수 없다”는 시스템의 전제가 깨졌다는 의미였다.
그런데 이 서비스에는 이미 겹침 검증 로직이 있었다. 모든 생성/수정 경로에서 시간이 겹치는 예약이 있으면 예외를 던지도록 구현되어 있었다.
그러면 검증을 통과한 중복 데이터는 어떻게 들어간 걸까?
1단계: 범인 찾기
먼저 DB에서 시간이 겹치는 예약을 직접 찾아봤다.
SELECT a.id, b.id, a.room_id, a.day_of_week,
a.start_time, a.end_time, b.start_time, b.end_time
FROM room_booking a
JOIN room_booking b
ON a.room_id = b.room_id
AND a.day_of_week = b.day_of_week AND a.id < b.id
AND a.start_time < b.end_time AND b.start_time < a.end_time
WHERE a.booking_type = 'MEETING_ROOM'
AND b.booking_type = 'MEETING_ROOM';
딱 1건. 3A 회의실의 금요일에 두 개의 예약이 겹쳐 있었다.
| id | 시간 | 비고 |
|---|---|---|
| 301 | 09:00-12:00 | 히스토리 있음 |
| 309 | 10:00-11:30 | 히스토리 없음 |
2단계: 히스토리 추적
id 301은 생성 히스토리가 정상적으로 남아있었다. 문제는 id 309 — 히스토리가 아예 없었다.
변경 이력 테이블을 뒤져보니 단서가 나왔다.
201 | CREATE | 3A [금] 09:00-12:00 | 05:40:08.684 | booking_id=301
203 | CREATE | 3A [월,수,금] 10:00-11:30 | 05:40:08.690 | booking_id=305
히스토리 203을 보면 “월,수,금 10:00-11:30”인데 booking_id=305(월요일)만 기록되어 있다. 반복 예약 API로 월/수/금 3개를 한 번에 만들었지만, 히스토리는 첫 번째 것에만 남겼기 때문이다. id 309(금요일)은 같은 반복 예약의 세 번째 — 감사 로그에서 보이지 않는 유령이었다.
그리고 타임스탬프를 보면 — 두 히스토리의 차이가 0.006초다.
3단계: 0.006초의 비밀
사람이 0.006초 간격으로 두 번 클릭하는 건 불가능하다. 코드가 병렬로 요청을 보낸 거다.
확인해보니 프론트엔드에서 여러 시간대를 저장할 때, API 호출을 병렬로 발사하고 있었다. 서버에서는 이 요청들이 각각 별도 트랜잭션으로 처리되는데, MySQL의 기본 격리 수준인 REPEATABLE READ에서는 다른 트랜잭션의 미커밋 데이터를 볼 수 없다.
요청A: [──겹침 검증──][──저장──][커밋]
요청B: [──겹침 검증──][─────저장─────][커밋]
↑
이 시점에 요청A는 아직 커밋 안 됨
→ 겹침 검증을 통과해버림
검증 로직은 완벽했다. 단일 트랜잭션 안에서는. 문제는 동시 트랜잭션 간의 가시성이었다.
원인은 파악했다. 그런데 근본 원인을 고치려면 API를 재설계해야 한다. 여러 시간대를 개별 요청으로 보내는 구조 자체가 문제이기 때문이다. 그건 시간이 걸린다.
지금 당장 해결해야 할 건 다른 거다 — 대시보드가 96번째 크래시 중이다.
즉시 대응: 크래시를 경고로 바꾸기
중복 데이터가 왜 들어갔는지는 알았다. 근본 원인을 고치는 건 그다음이다. 지금 급한 건 있으면 안 되는 데이터가 있을 때 서비스가 죽지 않게 만드는 것이다.
크래시가 발생한 JPA 쿼리의 반환 타입이 Optional<RoomBooking>이었다. 결과가 2개 이상이면 JPA가 NonUniqueResultException을 던진다. 이 예외를 아무도 잡지 않으니 API 전체가 500을 반환한다.
수정은 간단하다. 반환 타입을 List로 바꾸고, 중복이 감지되면 Sentry WARNING을 보내면 된다.
// 수정 전 — 중복 데이터가 있으면 크래시
Optional<RoomBooking> booking = repository
.findCurrentRoomBooking(roomId, dayOfWeek, time);
// 수정 후 — 중복이 있어도 서비스는 계속 동작
List<RoomBooking> bookings = repository
.findCurrentRoomBooking(roomId, dayOfWeek, time);
if (bookings.size() > 1) {
log.warn("Duplicate room booking detected - roomId: {}, day: {}, time: {}",
roomId, dayOfWeek, time);
Sentry.captureMessage(
"Duplicate room booking detected - roomId: " + roomId,
SentryLevel.WARNING);
}
return bookings.isEmpty() ? null : bookings.get(0);
이제 같은 상황이 다시 발생해도:
- 서비스는 죽지 않는다. 첫 번째 결과를 사용해서 정상 응답한다.
- 알림은 온다. Sentry WARNING으로 중복 발생을 감지할 수 있다.
- 사후 정리가 가능하다. 알림을 받고 DB에서 중복 데이터를 정리하면 된다.
크래시 96건이, 경고 1건으로 바뀌는 거다.
부수 수정: 감사 로그의 사각지대
원인을 추적하면서 한참 헤맸던 이유가 있다. id 309의 히스토리가 아예 없어서 “이 데이터가 어디서 왔는지”를 알 수 없었다.
반복 예약을 만들 때 월/수/금 3개가 생성되지만, 히스토리는 첫 번째(월요일)에만 기록되고 있었다. “대표 1건만 기록하면 되지”라는 판단이었겠지만, 장애 추적 관점에서는 치명적인 사각지대였다.
벌크 생성 시 모든 레코드에 개별 히스토리를 기록하도록 수정했다. 로그 한 줄이 더 생기는 비용보다, 장애 시 원인을 추적할 수 없는 비용이 훨씬 크다.
근본 원인은 나중에 고쳤다
방어적 쿼리를 배포해서 서비스를 안정화한 후, 근본 원인을 해결했다. 여러 시간대를 개별 API 호출로 보내던 구조를, 하나의 요청에 모든 시간대를 담아 보내는 Multi-Slot API로 재설계했다. 서버가 단일 트랜잭션 안에서 교차 검증까지 처리하니, 구조적으로 레이스 컨디션이 발생할 수 없다.
처음에는 프론트엔드에 await를 추가해서 요청을 순차 실행하는 것으로 해결했다고 생각했다. 하지만 이건 우회책이지 근본 해결이 아니었다. “여러 요청을 순서대로 보내기”가 아니라 “애초에 요청을 하나로 만들기”가 정답이었다.
교훈
1. 서비스 안정화가 먼저, 근본 해결은 그다음이다
프로덕션이 죽고 있는데 근본 원인부터 고치겠다고 API를 재설계하면 안 된다. 먼저 크래시를 멈추고, 그다음에 원인을 고친다. 이번에는 반환 타입 하나 바꾸는 것으로 서비스를 살릴 수 있었다.
2. Optional은 단일 결과를 보장하지 않는다 — 강제할 뿐이다
JPA에서 Optional 반환 타입은 “결과가 0 또는 1개”라는 가정이 깨지면 예외를 던진다. 비즈니스 로직상 단일 결과를 기대하더라도, 데이터 정합성이 깨질 가능성이 있다면 List로 받아서 방어하는 편이 안전하다.
3. Sentry는 발견만이 아니라 모니터링 도구다
이번에 Sentry는 두 번 역할을 했다.
- 발견:
NonUniqueResultException96건으로 장애를 알려줬다. - 감시: 수정 후에도
captureMessage(WARNING)으로 중복 발생을 계속 감시한다.
에러가 터졌을 때 잡아주는 것도 중요하지만, “에러는 아닌데 주의가 필요한 상황”을 WARNING으로 보내는 것도 Sentry의 핵심 활용법이다.
4. 감사 로그에 사각지대가 있으면 장애 추적이 막힌다
벌크 작업에서 “대표 1건만 기록”하면 나머지는 추적 불가능하다. 이번에 실제로 원인 분석을 막았다. 로그는 빠짐없이 남겨야 한다.
검증 로직이 완벽해도, 데이터가 깨질 수 있다. 그때 서비스가 죽느냐, 경고를 보내느냐는 방어적 코드 한 줄 차이다.
Comments